
전이 학습 기반 언어 모델
Transfer Learning(전이 학습)
주어진 학습 데이터는 적은데 모델의 정확도와 학습 속도를 높이고 싶을 때 사용하는 학습 방법입니다. 학습하려는 데이터와 유사한 데이터가 많을 때, 혹은 유사한 데이터로 학습한 모델이 이미 존재할 때 이를 이용하는 방식입니다.

Attention Mechanism(어텐션 메커니즘)

기본 아이디어
디코더에서 단어를 예측하는 시점마다(time step) 인코더에서 전체 문장을 다시 한번 본다는 것입니다.
단, 전체 문장을 전부 동일한 비율로 보는 것이 아니라, 연관된 부분을 집중해서 보는 것입니다. 그래서 집중(Aattention) 메커니즘이고, 결국 Task를 더 잘 풀기 위해 제안되었습니다.
전이 학습을 이용한 언어 모델
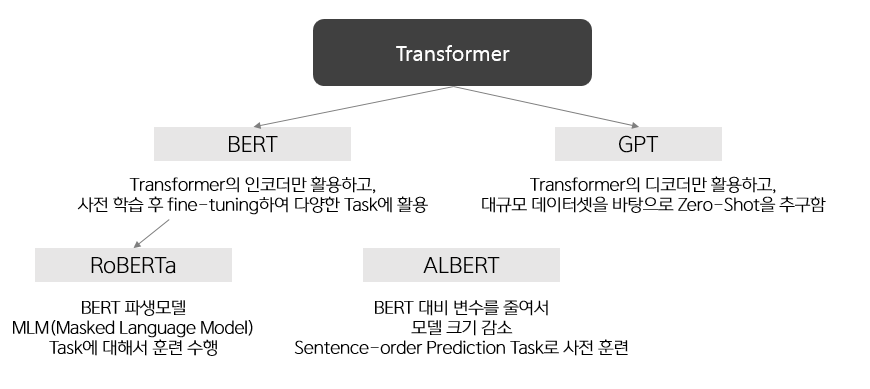
전이 학습을 이용한 모델에는 대표적으로 BERT와 GPT가 있고, BERT의 파생 모델로 RoBERTa, ALBERT가 있습니다. 언어 모델에는 편향성이 존재한다고 알려져 있습니다. 이를 측정하는 방법으로 제시된 것은 다음과 같습니다.
편향 측정 방법
1. StereoSet: Measuring stereotypical bias in pretrained language models
(Nadeem et al., ACL-IJCNLP 2021)
성별, 직업, 인종, 종교의 네 가지 영역에서 고정관념을 측정하기 위해 영어 데이터 세트인 StereoSet가 있습니다. BERT, GPT-2, RoBERTa 및 XLnet과 같은 모델의 편향과 언어 모델링 능력을 비교하여 사전 훈련된 언어 모델의 편향을 평가하여였습니다.
문장 간, 문장 내에서 사전 학습된 언어 모델의 모델링 능력과 고정관념을 함께 보았고, 타겟 용어에 대한 연관된 3가지 중(stereotype, anit-stereotype, unrelated) 중 어떤 것을 선택하는지에 따라 모델의 편향을 평가했습니다.
결과적으로 언어 모델의 모델링 능력이 향상됨에 따라 고정관념도 심화된다는 것을 보여주었습니다.
2. K-SteroSet
영어 기반 모델의 편향을 평가하기 위해 MIT에서 구축한 SteroSet을 보완하여 서울대학교 전기정보공학부 윤성로 교수님이 개발한 한국어 데이터셋입니다. 약 4,000개 샘플로 구성된 원본 데이터셋을 네이버 파파고 API로 1차 번역하고, 연구팀에서 독립적으로 검수하며, 원본 샘플 양식과 취지를 보존하도록 후처리해 데이터셋을 구축했습니다.
기존 StreoSet과 동일하게 성별, 직업, 인종, 종교의 네 가지 영역에 대한 고정관념을 측정하였고, 편향성 진단을 위한 샘플은 두 개 카테고리로 분류했습니다.
모델에 빈칸 처리된 문장을 보여주었을 때 빈칸에 채워질 내용으로 세 개의 보기 중 어느 것에 높은 점수를 부여하는지를 통해 편향성을 진단했습니다.
'스터디 > Generative AI' 카테고리의 다른 글
| [Generative AI] Chat GPT (0) | 2023.03.29 |
|---|---|
| [Generative AI] Generative AI(생성 AI) (0) | 2023.03.28 |


댓글