
Deep Learning 딥러닝 기본 이해
| Layer Level | Model Level |
| Manifold Learning(매니폴드 학습) | Representation Learning(표현 학습) |
| Transfer Learning(전이 학습) | Meta Learning(메타 학습) |
| Semi Supervised Learning(반지도 학습) | Self Supervised Learning(자기 지도 학습) |
| Transformer(트랜스포머) | Attention Mechanism(어텐션 메커니즘) |
Semi Supervised Learning(반지도 학습) and Self Supervised Learning(자기 지도 학습)

Supervised Learning의 한계
딥러닝의 가장 대표적인 방법론은 supervised learning (지도학습)이나, 학습 데이터의 패턴을 외우는 학습법에 불과합니다. 지도학습을 일반화하기 위해서는 많은 labeled data가 필요하나, labeled data를 확보하기 어려운 분야에서는 높은 모형 성능을 기대하기 어렵다는 한계점이 존재합니다.
결국 학습데이터에는 없는 새로운 데이터는 학습 모형이 작동하지 못할 가능성이 존재합합니다. 이를 해결하고자 나온 것이 Unsupervised Learning(비지도) / Semi-Supervised Learning(반지도) / Self-Supervised Learning(자기 지도) 입니다.
Semi Supervised Learning(반지도 학습)
Label Data와 Unlabeled Data를 모두 사용하며 한쪽의 데이터에 있는 추가 정보를 활용해 다른 데이터 학습에서의 성능을 높이는 것을 목표로 합니다.

Self Supervised Learning(자기 지도 학습, SSL)
자기 지도학습은 최소한의 데이터만으로 스스로 규칙을 찾아 분석하는 것을 말합니다. 사람이 별도로 지도하지 않아도, 기계가 스스로 대상을 인지하고 의미를 부여합니다.
자기 지도 학습 이하 SSL을 이해하기 위해서는 기본 용어를 알아야 합니다.
기본 용어에는 Human-annotated Label, Pretext Task, Pseudo Label, Downstream Task가 있습니다.
Human-annotated Label
사람이 직접 레이블링을 한 (어떤 사진인지 구분해 둔) 것들을 의미합니다.
Pretext Task
무언가 문제를 풀기 위해서 pre-designed 된 tasks를 의미합니다.
Pseudo Label
Pretext Tasks를 위해 Data Attributes 가 된 것들의 레이블을 의미합니다. 예를 들면 일부 사진을 90도 회전시킨 뒤 Pseudo Label을 '90도'라고 정의하는 것을 말합니다.
Downstream Task
Self-supervised learning으로 학습된 Features들이 얼마나 잘 학습되었는지 판단하기 위해 사용되는 Task입니다. (Classification/Regression 등)
일반적인 SSL 방법론의 절차는 다음과 같습니다.
1. Pretext task (사용자가 직접 정의한 Task)를 정의합니다.
2. Label이 없는 데이터셋을 사용하여 Pretext task를 목표로 모델을 학습시키며, 데이터 자체의 정보를 적당히 변형/사용하여 이를 기반으로 학습합니다.
3. 2에서 학습시킨 모델을 Downstream task에 가져와 Weight는 Freeze 시킨 채로 전이학습을 수행합니다.
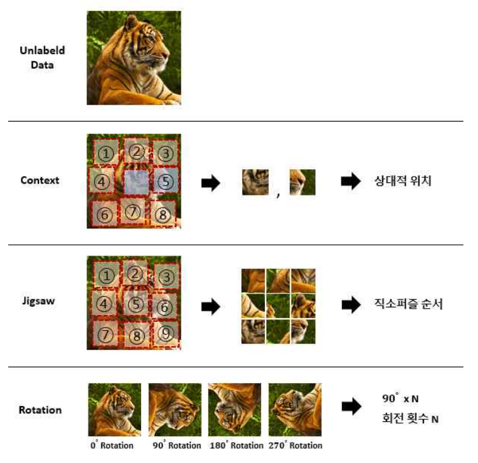
SSL 방법
SSL방법에는 Energy-based model (EBM), Joint embedding architecture, Contrastive Learning, Contrastive Predictive Coding, Instance Discrimination Methods, Contrasting Cluster Assignments가 있습니다.
Joint embedding architecture

거리 기반의 학습 모형: Siamese Networks
Twin Network로 구성되며, 서로 동일한 구조를 가지며 Weight와 Network Parameter를 공유합니다.

Contrastive Learning
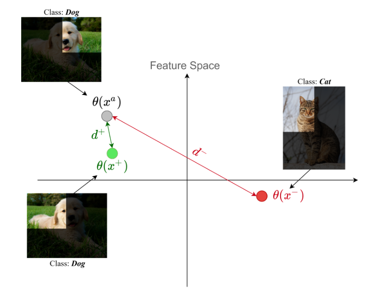
“Anchor"라고 하는 입력(텍스트, 이미지, 비디오 세그먼트와 같은)을 긍정적 및 부정적 예와 대조하여 모델을 학습합니다. 양의 표본은 앵커와 같은 분포에 속하는 표본을 말하며, 음의 표본은 앵커와 다른 분포를 가진 표본을 의미합니다.
Instance Discrimination Methods

Anchor-positive Pair 사이의 거리는 최소화하고, Anchor-negative Pair 사이의 거리는 최대화하는 것입니다. 대표적으로 SimCLR, MoCo 방법이 있습니다.
'스터디' 카테고리의 다른 글
| [AI] Deep Learning 딥러닝 기본 이해_BERT(Bidirectional Encoder Representation Transformer) (0) | 2023.06.17 |
|---|---|
| [AI] Deep Learning 딥러닝 기본 이해_Attention Mechanism (0) | 2023.06.17 |
| [AI] Deep Learning 딥러닝 기본 이해_One-Shot / Few-Shot / Zero-Shot Learning (0) | 2023.06.15 |
| [AI] Deep Learning 딥러닝 기본 이해_전이 학습과 메타 학습 (0) | 2023.06.15 |
| [AI] Deep Learning 딥러닝 기본 이해_매니폴드 학습과 표현 학습 (0) | 2023.06.15 |




댓글